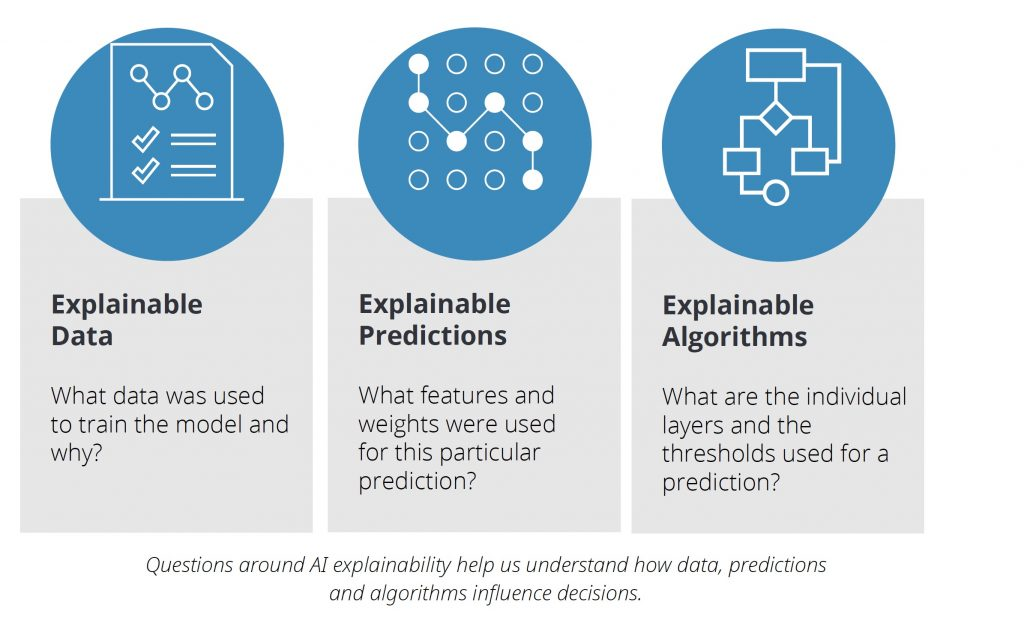
Need of Explainable AI
Let’s say you are a reputed doctor to whom a Data Scientist comes and says -
“Hi, I’ve built a model to predict if a person has skin cancer or not. You should set it up in your hospital.” Will you completely trust the person?
Many questions might arise in your mind -
On what basis does this model classify an image as cancerous? How reliable is it? Will it be more helpful than the cancer experts we have here?
Even the Data Scientist might not be able to answer your questions well.
So what should be done to know how trustworthy a model is? Can we help the Data Scientist out?
Simply going by the name, it explains what exactly is happening behind the fancy Artificial Intelligence models.
A formal definition:
“Explainable AI is a set of tools and frameworks to help you understand and interpret predictions made by your machine learning models. With it, you can debug and improve model performance, and help others understand your models' behaviour”
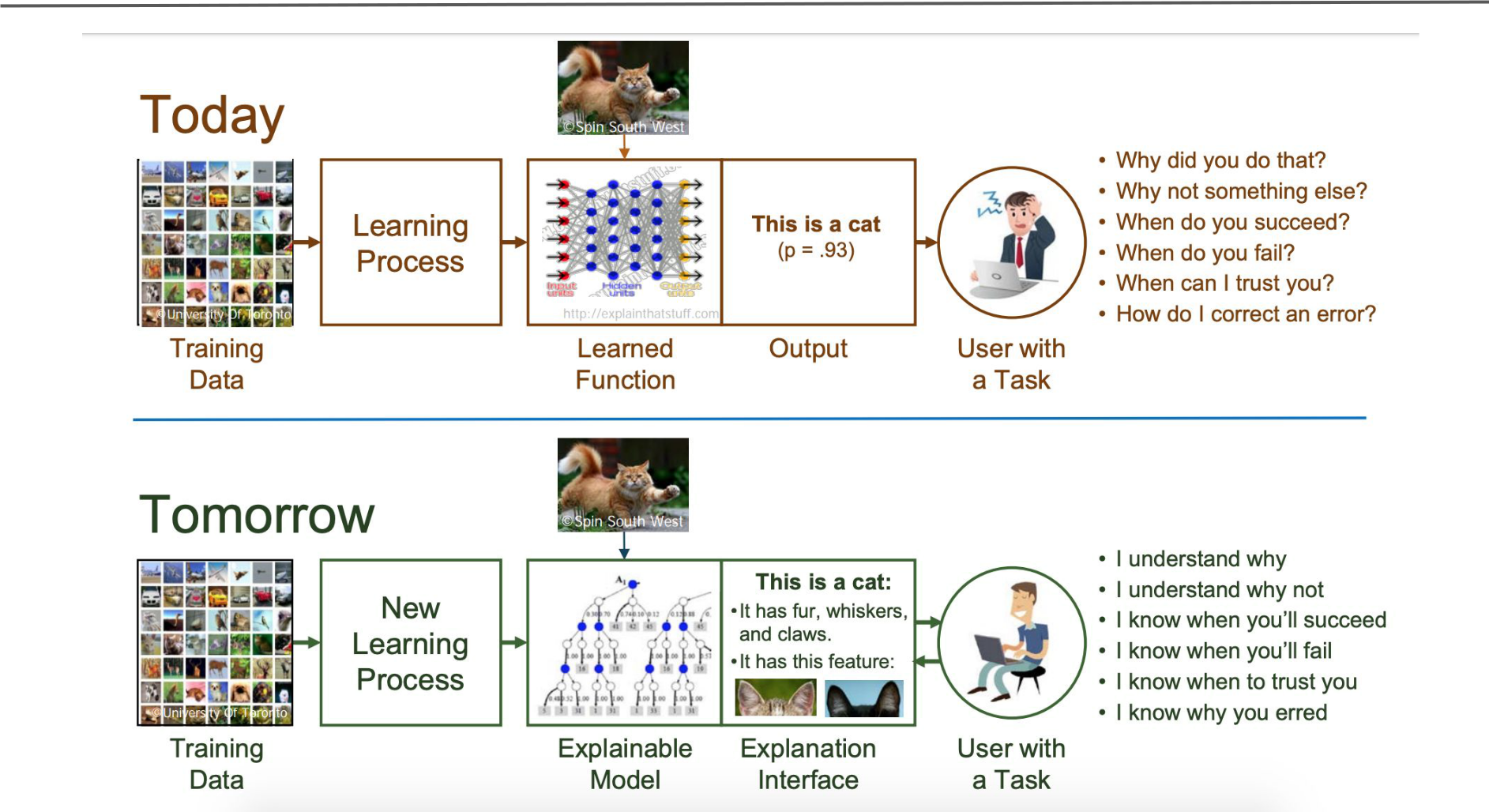
Since the start of the path to the mainstream adoption of AI, it has been common practice to train machine learning models with a black-box approach — as long as they give us good results, it doesn’t matter if we can’t explain them.

Now, the focus is slowly turning towards the transparency and explicability of these models. We want to know WHY they come up with the predictions they output. Explainable AI is one of the ‘hottest’ topics in the field of Machine Learning nowadays.
What is causing the transition?
- Understanding what happens when Machine Learning models make predictions could help speed up the widespread adoption of these systems. New technologies always take time to become mature, but it definitely helps if they are understood.
- It makes users become increasingly comfortable with the technology, and removes the magical veil which seems to surround AI. Having users that trust the systems that they are using is of utmost importance.
- For some sectors like insurance or banking, there are sometimes company-level or even legislative restrictions that make it a must for the models that these companies use to be explainable.
- In some other critical areas, like medicine, where AI can have such a great impact and make amazing improvements to our quality of life, it is fundamental that the used models can be trusted without a hint of a doubt. Having a Netflix recommendation system that sometimes outputs strange predictions might not have a very big impact, but in the case of medical diagnosis, strange/wrong predictions could be fatal. Providing more information than just the prediction itself, allows the users to decide whether they trust the prediction or not.
- Explainable models can help their users make better use of the outputs such models give, making them have even more impact in the business, research or decision making. We should always have in mind that like any other technology, the goal of AI is to improve our quality of life, so the more benefit we can extract from it, the better.
Model Interpretation is something which can make or break a real-world machine learning project in the industry. It helps us come one step closer to explainable artificial intelligence (XAI).
Interpretability is the degree to which a human can understand the cause of a decision.
Model interpretation tries to understand and explain the decisions taken by the model, i.e., the what, why and how. The three most important aspects of model interpretation are:
- Transparency
- The ability to question
- The ease of understanding
Let’s start by defining exactly what it means to interpret a model. At a very high level, we want to understand what motivated a certain prediction.
For instance, let's use the problem from the XGBoost documentation, where, given the age, gender and occupation of an individual, I want to predict whether or not they will like computer games:
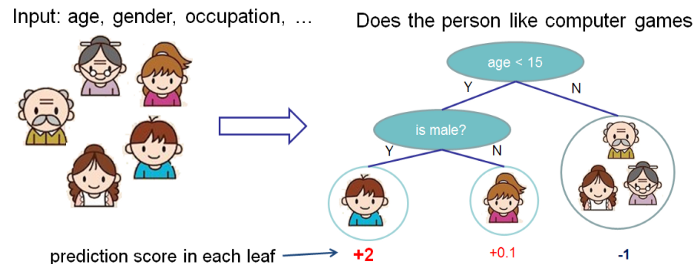
In this case, my input features are age, gender and occupation. I want to know how these features impacted the model’s prediction that someone would like computer games.
However, there are two different ways to interpret this:
On a global level:
Looking at the entire dataset, which features did the algorithm find most predictive?
XGBoost’s get_score() function - which counts how many times a feature was used to split the data – is an example of considering global feature importance, since it looks at what was learned from all the data.
On a local level:
Maybe, across all individuals, age was the most important feature, and younger people are much more likely to like computer games.
But if Frank is a 50-year-old who works as a video game tester, it’s likely that his occupation is going to be much more significant than his age in determining whether he likes computer games. Identifying which features were most important for Frank specifically involves finding feature importances on a ‘local’ – individual – level.