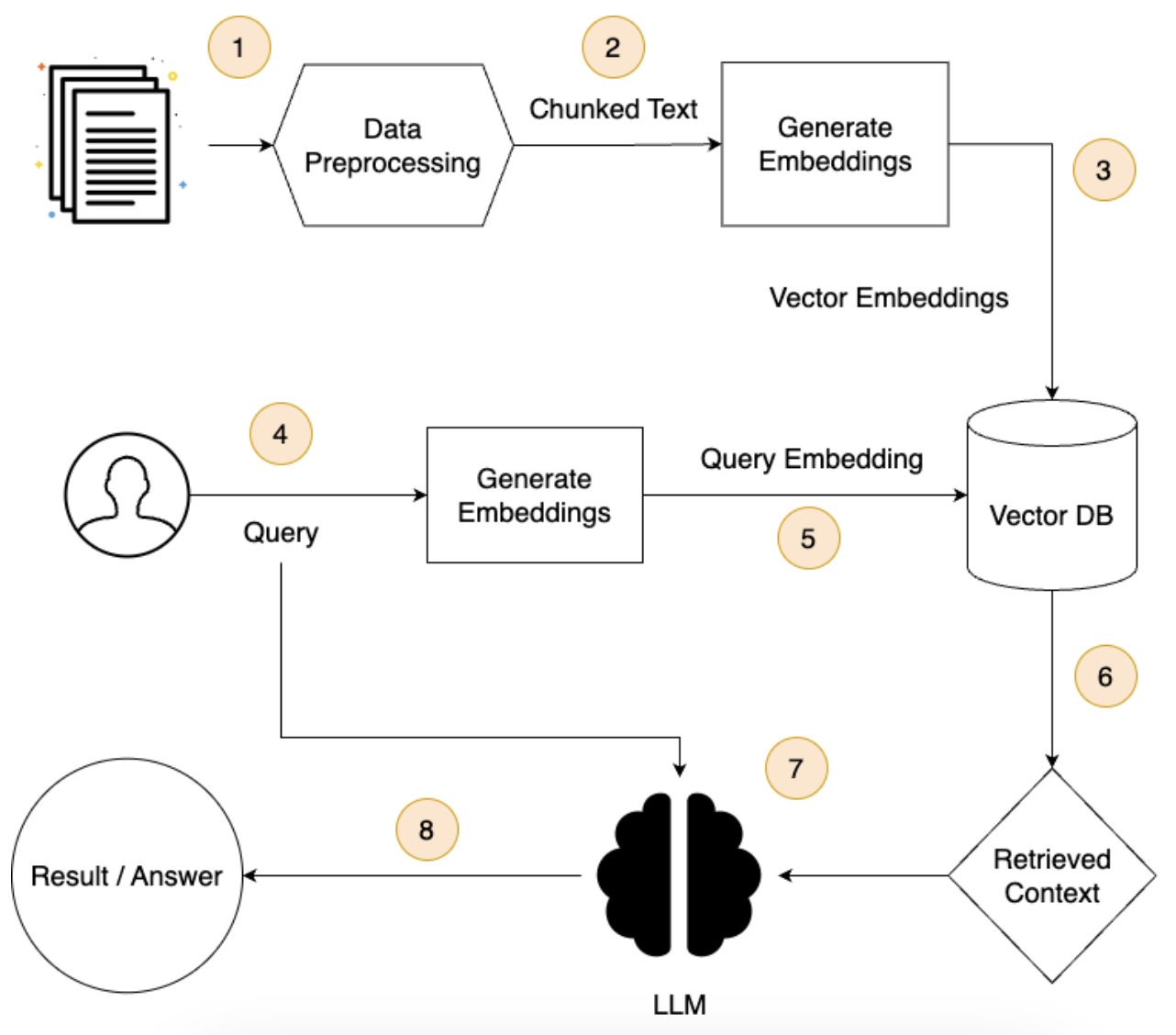
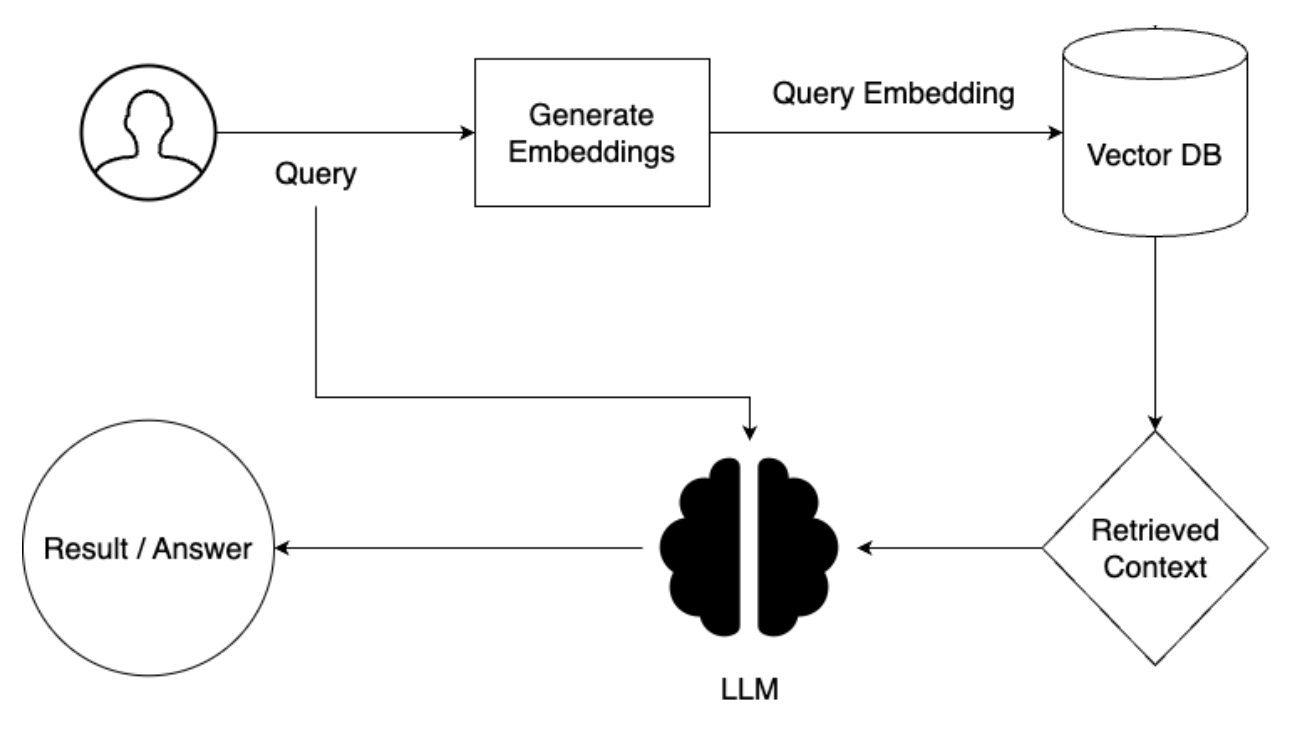
- Everything in an RAG pipeline begins with a source document that contains the information needed for content generation.
- The embedding model converts the chunked (by text-splitters) textual content of the source document into a series of numbers, making them feasible by algorithms.
- These numbers are then stored in a vector database in such a way that the required information can be efficiently searched to find relevant text embeddings.
- When a query or prompt is received, the retriever uses the embedding of the prompt to fetch the most relevant document embeddings from the vector database using similarity search and other methods.
- The Large Language Model (LLM) then takes the retrieved documents as an augmented input along with the original prompt, using both to generate an informed response.
Loading the data
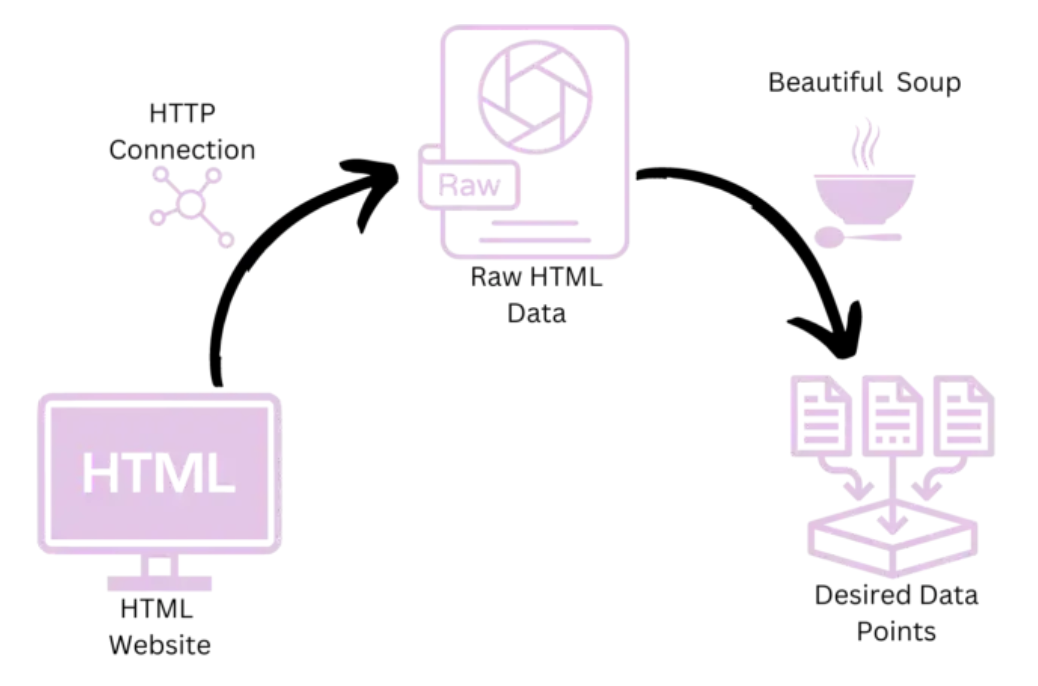
Initially, our text may be stored in various formats like PDF, webpage, CSV, or Readme files. Our first task is to load or extract the text from these different formats. The frameworks we'll explore later offer various functions tailored to each file type.
For instance, if we're dealing with a web page, we might need to identify specific class names or IDs within the HTML structure to extract relevant information. This process, known as scraping, allows us to retrieve data from the webpage. While this example focuses on webpage extraction, the frameworks we'll explore later will provide similar tools for extracting text from other file formats.
Processing the Data
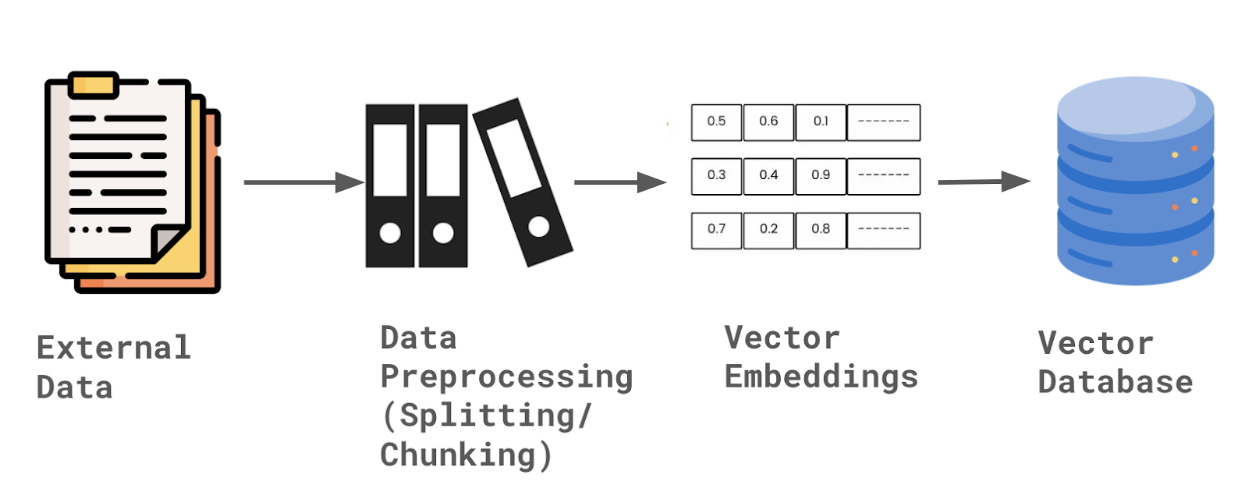
Once the necessary data is extracted, it's important to divide the text and conduct feature engineering (if required). This involves breaking down the data into smaller chunks because whatever Large Language Model is used, will have a context length or context window, beyond which it fails to recall information.
Just as it's challenging to remember the beginning of a 300-page PDF while reading its end, Large Language Models (LLMs) face difficulties retaining large volumes of text simultaneously. To enhance comprehension and context retrieval, we employ a text splitter or something similar.
In the text splitters, we use a chunk size and chunk overlap to determine how the text will be broken. Chunk size determines the maximum character limit per chunk, while chunk overlap specifies the number of characters shared between adjacent chunks. These parameters control how finely the text is split – smaller sizes yield more chunks and larger overlaps produce more shared characters among chunks.
Creating embeddings and storing them
Once our text is split into smaller chunks, we require a tool to transform it into numerical embeddings. This process is vital because, during data retrieval, the retriever tool scans the vector database using similarity search and other methods, enhancing the efficiency of text retrieval. It's crucial to recognize that computers interpret text differently than humans; they understand only numbers, represented by 0s and 1s. Thus, to bridge this gap, we must convert text into numerical embeddings.
After creating the numerical embeddings, we store them in the vector database. Vector embeddings are essentially arrays of data that are stored within the database. Any complex object, whether it's an image, text, or audio, is converted into numerical representations and then stored in the vector database.
Retrieving the relevant data
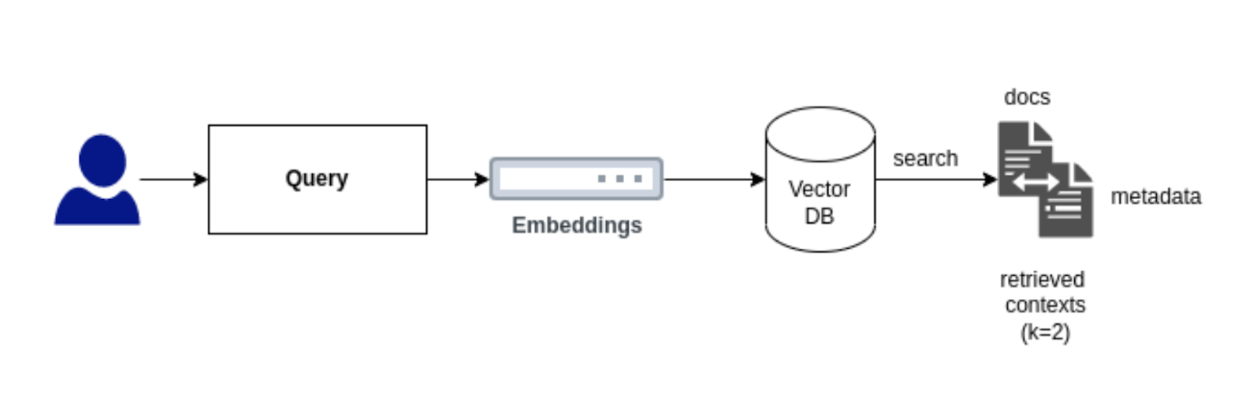
A retriever is an interface that provides documents based on an unstructured query. It's broader in scope compared to a vector store, as it doesn't necessarily store documents but retrieves them upon request.
We do have the option to query our database directly and extract information using methods like similarity search and vector-based similarity search using the vector store. Additionally, using a prompt alongside the retriever can improve retrieval efficiency. By offering context through the prompt, the retriever can pinpoint relevant documents more effectively.
Generating output
After obtaining the retrieved data, we utilize Chains to apply the defined prompt template and incorporate the context provided by the retrieved documents. This mechanism enables us to generate responses using both the prompt template and the Large Language Model (LLM).
Here is the diagram of the retriever section of the RAG pipeline.
Don't get confused! Try reading through this process again to understand the flow.
