So, what exactly is Chunking?
Imagine providing a PDF book to someone to summarize its key concepts. However, you discover that this person recalls mainly the concepts from the book's final chapters and not much from the earlier ones. This situation is common for all of us. Without revisiting concepts, it's challenging to remember them, especially if we consume a significant amount of information afterward. This memory timeframe is known as a context window or context length. Similarly, LLMs also have a context length, beyond which they struggle to retain information.
To address this challenge, we use text-splitting. This technique involves dividing the entire text corpus into smaller segments. These segments are sized to fit within the context window of the LLM we intend to use. In short, the length of the segments is reduced to be smaller than the context length of the LLM.
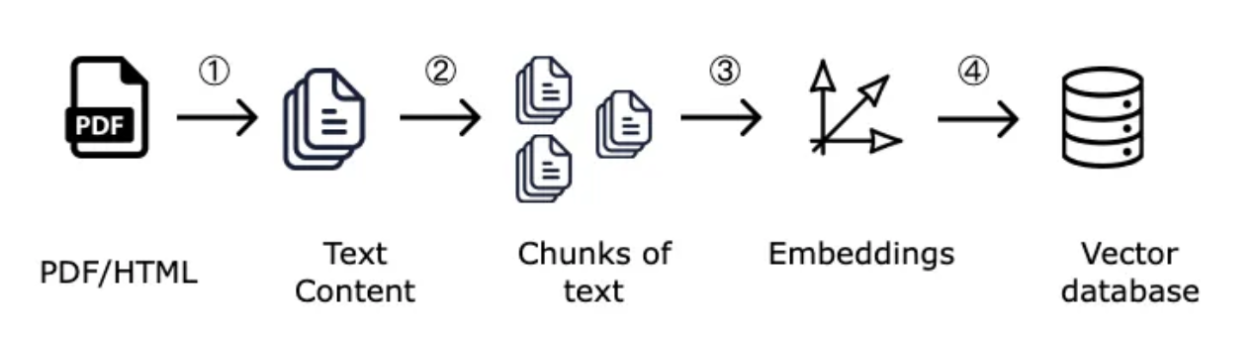
But how should we chunk a large text?
Consider the paragraph below:
“Nature is like a big playground! where animals, birds, and insects live and play together. Imagine a beautiful forest with tall trees where birds sing songs all day. There are animals like - squirrels who jump from tree to tree, and rabbits who hop around in the grass.”
Consider splitting the text at regular intervals of each character. This approach involves breaking the text into chunks once a certain threshold is reached, and continuing this process. By following this strategy, the chunked text will appear as follows:
“Nature is like a big
playground! where a
nimals, birds, and i
nsects live and play
together. Imagine a
beautiful forest wi
th tall trees where
birds sing songs all
day. There are anim
als like - squirrels
who jump from tree
to tree, and rabbits who hop around in t he grass.”
Now, let's consider chunking the text based on punctuation marks. Whenever a punctuation mark such as ',', '.', '-', etc. appears, the text is split accordingly. Applying this method yields the following chunked text:
“Nature is like a big playground!
where animals,
birds,
and insects live and play together.
Imagine a beautiful forest with tall trees
where birds sing songs all day.
There are animals like -
squirrels who jump from tree to tree,
and rabbits who hop around in the grass.”
As you can see, even with this method, individual chunks like "bird" and "where animals" lack contextual meaning, potentially leading to irrelevant outcomes when processed by the LLM.
CharacterTextSplitter from Langchain uses a similar method as described in the first approach. Additionally, it incorporates an overlap technique, where adjacent chunks share a section of text, resulting in repeated content between two connecting chunks, like the one shown below.

Next is the RecursiveCharacterTextSplitter which divides a large text into smaller chunks by utilizing a set of characters as the separator (with the default set including ["\n\n", "\n", " ", ""]). Initially, it attempts to split the text using the "\n\n" character. If the resulting splits are still larger than the specified chunk size, it proceeds to the next character, "\n", and repeats the splitting process. This process continues until a split smaller than the specified chunk size is obtained.
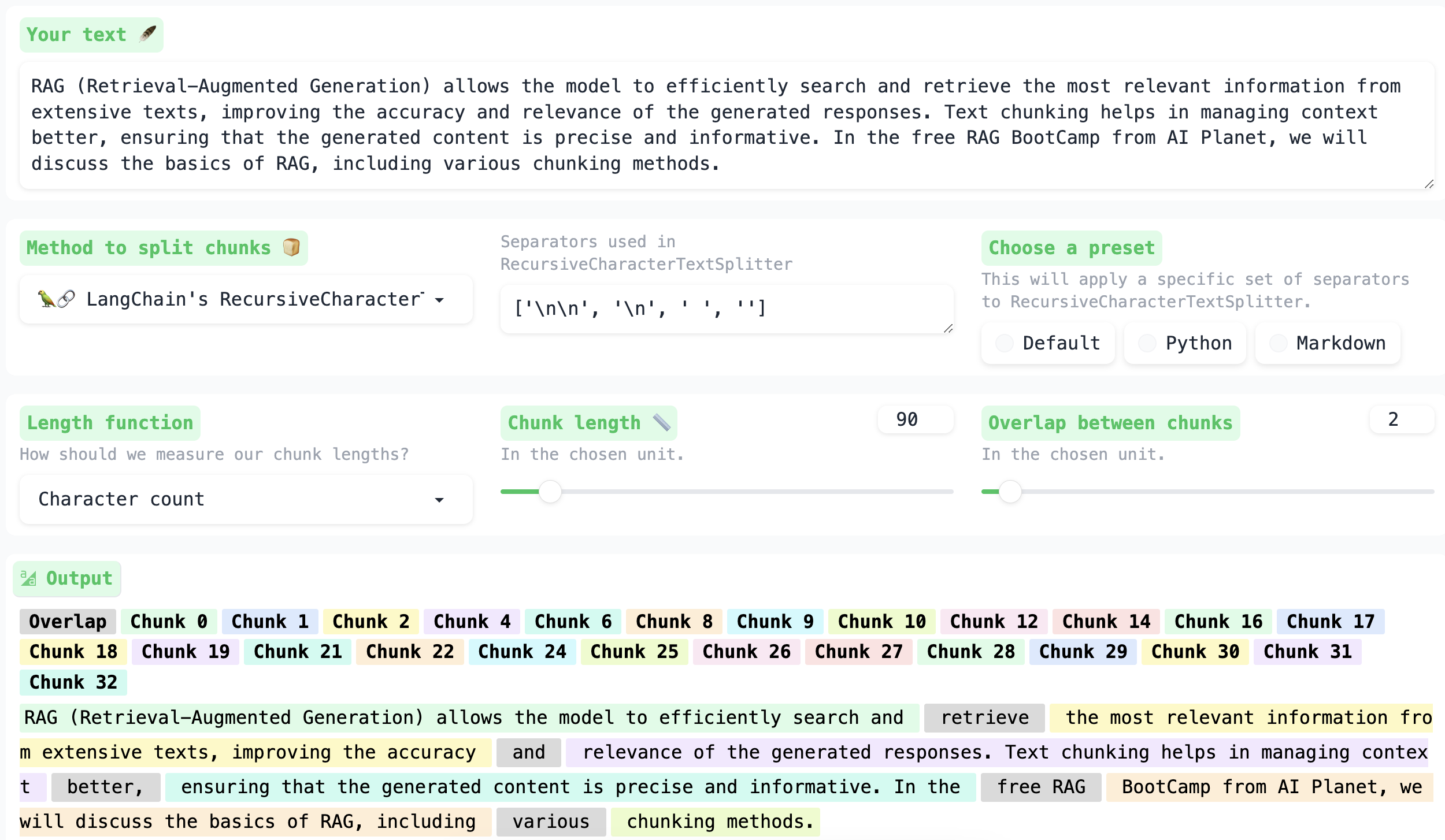
Suppose you have text stored in a more complex format like a PDF or Markdown file format and you need to extract and segment it. In such cases, the DocumentTextSplitter is more suitable as it accommodates diverse data formats. It operates similarly to the Recursive Character TextSplitter but uses distinct separators tailored for each file type. For instance, for Markdown files, it has specific characters as separators like:
- \n#{1,6} - Split by newlines followed by a header (H1 through H6)
- ```\n - Code blocks
- \n\\\*+\n - Horizontal Lines
- \n---+\n - Horizontal Lines
- \n___+\n - Horizontal Lines
- \n\n Double new lines
- \n - New line
- " " - Spaces
- "" - Character
Semantic chunking involves utilizing embeddings to assign meaning to textual data. By comparing the embeddings of two texts and calculating the distance or dissimilarity between them, we can determine their relatedness. This approach allows us to utilize semantic similarity for grouping or chunking text.
Agent-based chunking involves generating chunks that may not directly correspond to segments of the original text, but are re-created to convey meaningful statements independently. Unlike semantic chunking, which relies on embedding models, agent-based chunking utilizes a Large Language Model (LLM) to generate each chunk. These chunks can also be grouped to create bigger chunks with better context.
