Around 80% of the world's data exists in an unstructured format. This means that querying a relational database won't suffice to find and retrieve these types of data, for example, images of a cat through a text query. To effectively manage image data within these databases, we need to manually assign tags and unique identifiers to each image.
Vector databases offer a solution to this challenge by storing and indexing vector embeddings, enabling rapid retrieval and similarity search algorithms without the need to assign tags.
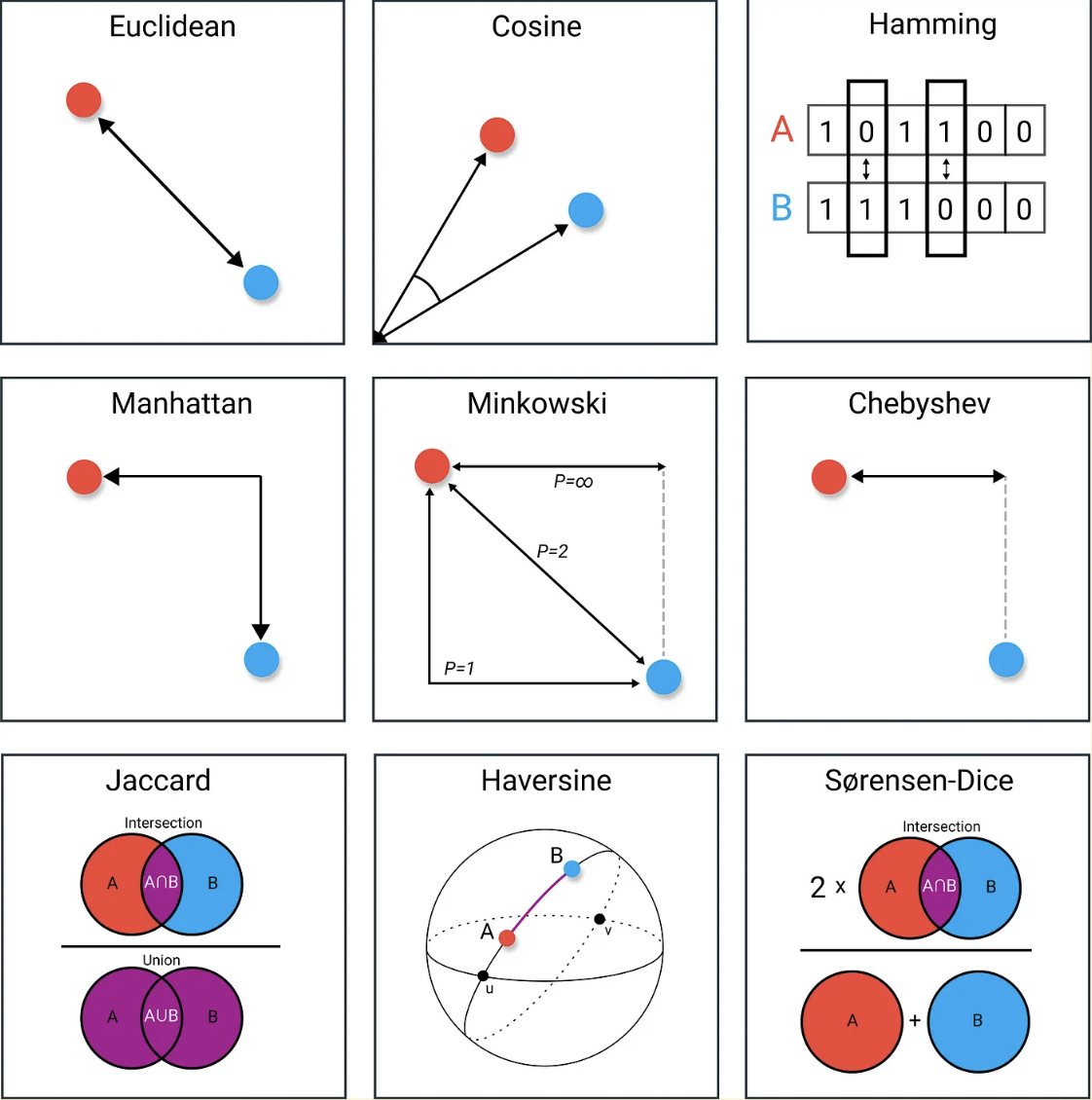
The process of calculating the distance between two vectors using formulas like Euclidean or Manhattan distance can be time-consuming and cumbersome.
To address this, vector stores utilize indexing for each vector embedding to facilitate swift retrieval.
Indexing involves converting high-dimensional vectors into low-dimensional indexes, thereby speeding up the search process. There are four common indexing techniques used for this purpose:
- Flat Indexing - Flat indexing is an index strategy where we simply store each vector as is, with no modifications. It works better and faster on a smaller dataset, by comparing every vector with the query vector.
- Locality Sensitive Hashing (LSH) indexes - Locality Sensitive Hashing is an indexing strategy that finds the approximate nearest neighbor, instead of doing an exhaustive search to find the actual nearest neighbor as is done with flat indexing. The index is built using a hashing function. Vector embeddings that are near each other are hashed to the same group.
- Cluster-based algorithm (IVF) - this reduces search complexity by mapping query vectors to smaller subsets of the vector space, achieved through partitioning and center-of-mass identification. However, edge cases where query vectors are near multiple clusters may result in having the actual result in another cluster.
- Hierarchical Navigable Small Worlds (HNSW) indexes - HNSW employs a multi-layered graph structure (as shown in the image below) to index data efficiently by grouping vectors based on similarity, reducing search complexity exponentially. Queries traverse layers, starting from the highest, to find the closest matches iteratively until reaching the lowest layer.
Vectors can be compared for similarity using methods such as cosine distance, Manhattan (L1) distance, Euclidean (L2) distance, or intersection over union.
Likewise, different search techniques can be employed during retrieval, tailored to the nature of the data stored in the vector database. Some of these techniques include:
- Similarity search - This approach takes either a textual string or numerical embeddings as a query and retrieves the most relevant document from the store through effective vector comparison and ranking.
- Maximum marginal relevance search (MMR) - This technique is utilized to prevent redundancy when fetching relevant items for a query. Rather than solely focusing on retrieving the most relevant items, which may be quite similar to each other, MMR aims to strike a balance between relevance and diversity in the retrieved items.
