What is fine-tuning and how to fine-tune a model?
Imagine someone who wants to create a personalized diet plan recommendation system. They start with a pre-trained language model as the foundation, which already has extensive knowledge about diet, nutrition, and food data from its pre-training on internet text. However, it lacks information about the individual's specific food preferences. So, the individual collects data on their likes and dislikes in the culinary domain. This data is then used to retrain the model, aligning its predictions based on the provided data. This is how the individual customizes the recommendation system for their use.
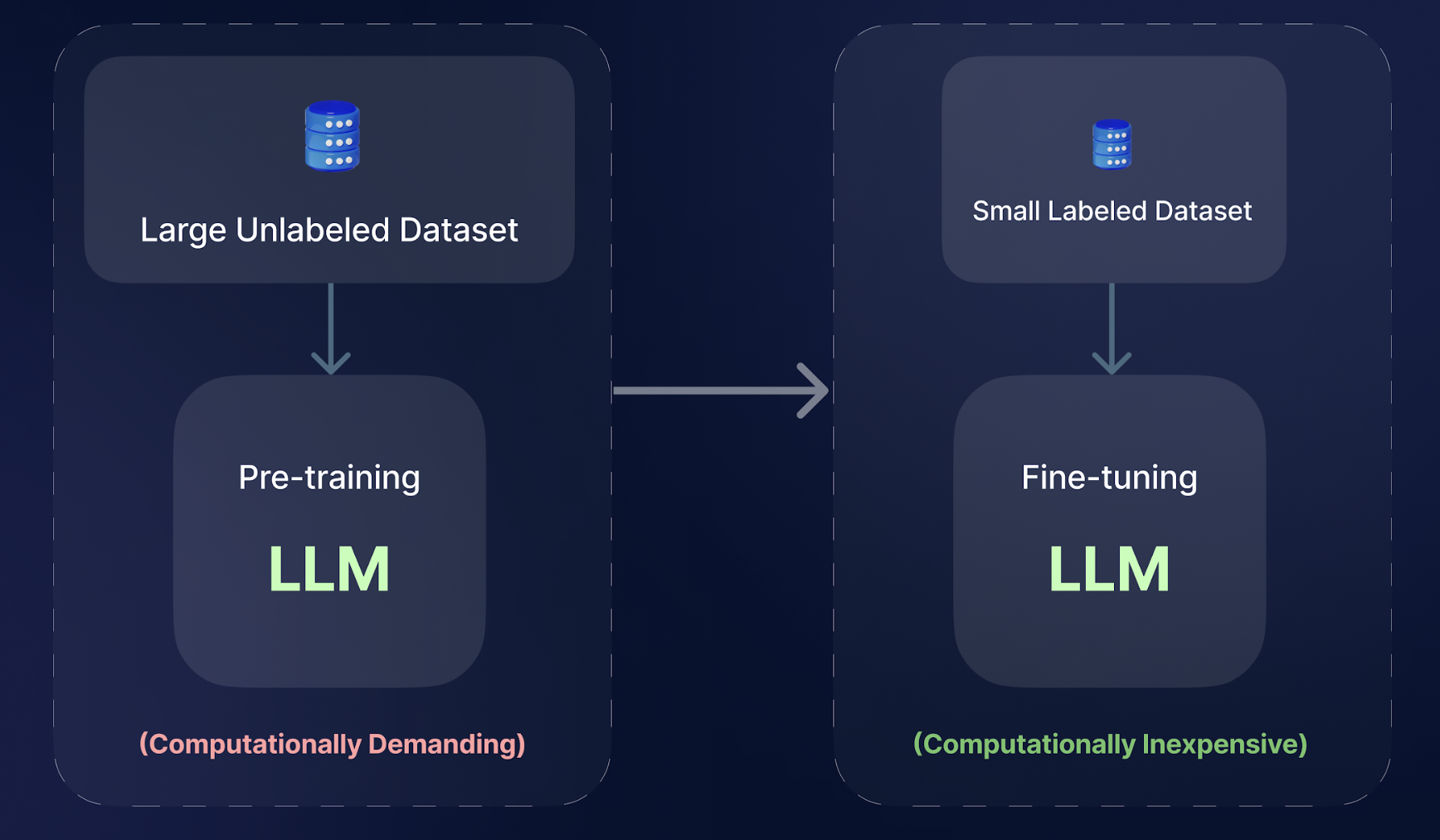
While pre-trained language models possess immense capabilities, they are not inherently specialized in any particular task. They need the refinement and alignment that fine-tuning offers. The advantage of fine-tuning lies in the fact that we don't need to know the model's architecture, number of layers, regularization, learning rate, or training methodology. We can simply treat the model as a black box with existing logic inside, which further learns from the data we feed it.
During the fine-tuning process, certain layers of the model or neural network undergo modifications internally. As training advances, the parameters of the entire model are adjusted, gradually refining the learned representations to better align with the new task or dataset.
Let's say, you want to create the diet recommendation bot, discussed above. To achieve this, there are several steps involved (apart from collecting the data):
- Text preprocessing: This involves preparing questions (regarding dietary preferences), along with their corresponding answers and contextual information. This process involves tokenizing the text (breaking it into smaller units), and formatting it adequately for the task. Typically, the question and context are encoded together, and the model generates output based on its predictions.
- Defining a fine-tuning objective: Specify a task-specific goal, such as Question Answering (QA), where the model's objective is to respond to questions by using the provided context.
- Hyper-parameter tuning: Explore different hyper-parameters such as batch size and training epochs through experimentation. Changing these parameters can have a significant impact on the model's performance. For example, a lower learning rate could result in finer adjustments to the model's parameters, whereas increasing the batch size may accelerate training but could demand more memory resources.
Issues with Fine-tuning
Despite fine-tuning, the model/LLM still retains a vast number of parameters, nearly comparable to those of the original pre-trained model. To address this issue, some approaches (like the Low-Rank Adaption in the Parameter Efficient Fine-tuning technique) attempt to modify only certain parameters or incorporate additional modules for specific tasks. This approach minimizes the storage and loading requirements, enhancing operational efficiency during deployment. However, these techniques frequently result in increased inference delay due to either expanding the model's depth or limiting its usable sequence length.
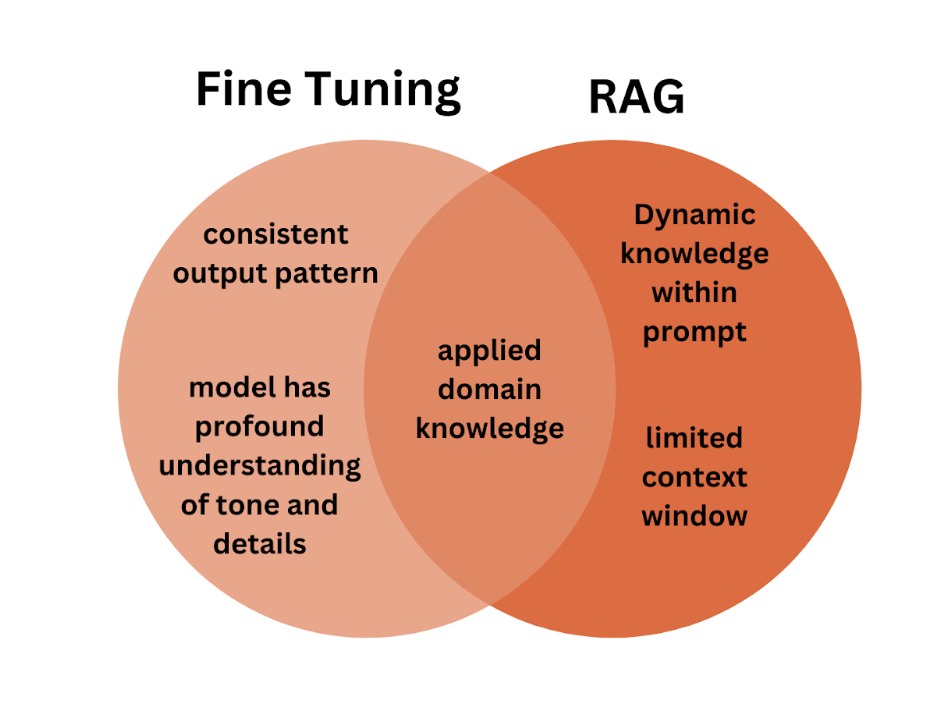
When should we use fine-tuning?
When considering fine-tuning an LLM, you should ask yourself whether you require a model with a profound grasp of the nuances of a specific domain or topic. If the answer is “yes”, then fine-tuning is the suitable approach. Additionally, fine-tuning can ensure a predictable response pattern and consistency, especially when dealing with abundant domain-specific data. Fine tuning is also useful for shortening context length by minimizing the prompt size with each query and it can also be used while limiting the scope of potential responses.
When should we use the RAG pipeline?
If you aim to incorporate specific information updates into your LLM, using an RAG pipeline would be a more efficient strategy. The RAG pipeline integrates dynamic knowledge but limits the context length through the additional prompt. RAG is more kind of knowledge transfer, where data is not fixed and keeps changing frequently.